Tacotron 2 #11
Comments
|
Paper (https://arxiv.org/abs/1712.05884) seems submitted to ICASSP 2018. I have read that today. It is very nice! I plan to implement WaveNet vocoder when I finish multi-speaker work (#10). DeepVoice3 and Tacotron2 both uses WaveNet vocoder. |
|
Great! I wish you luck with the multi-speak and vocoder work! :D |
|
I started to implement WaveNet vocoder. It's still quite WIP, but I think I implemented all basic features. If you are interested, check out https://github.com/r9y9/wavenet_vocoder. Audio samples from a model trained on CMU Arctic (16kHz, ~1200 utterances) can be found at r9y9/wavenet_vocoder#1 (comment). |
|
It turned out to be easy to implement WaveNet vocoder. I think my implementation is already feature complete. The problem is that I don't have 32 GPUs :( |
|
Yeah, it is really a bummer that the vocoder requires that much compute power to be able to train in a reasonable amount of time. :C Perhaps you could try the WORLD vocoder method they used here? http://www.dtic.upf.edu/~mblaauw/NPSS/ |
|
@r9y9 I had a listen to https://r9y9.github.io/wavenet_vocoder/ and I think that they sound really quite good! The samples are much better (to me at least) than the tacotron samples as they do not seem to have the same harsh "sound compression artifact" noise. They instead sound like they have lower quality microphones or recored on a lower quality analog tape. (I guess most of it has to do with the 16kHz sampling freq) So anyways, what changed? Did you buy 32 GPUs or did I missunderstand that it is not the wavenet vocoder itself that needs that much compute power? (IE it is tacotron + wavenet vocoder that requires that much) |
|
@DarkDefender Nothing changed:) I just trained WaveNets with my single GPU (GTX 1080Ti) . As I noted in the demo page, it took 22 hours to train for the single speaker version and 44 hours for the multi-speaker version. I used 1 ~ 7 hours of audio sampled at 16kHz. For larger and higher rate sampled data, it will take more time to train. |
|
@r9y9 Wow! The output audio in the samples files is very impressive. If you don't mind I'd like to ask a couple of questions. Recently I was browsing some repos that do style transfer with deepvoice, in particular this one does a nice job, have your tried that kind of think? Also, do you know of an already trained network that I can run locally or online in a Jupyter notebook to generate speech from text? Keep up the good work! |
|
We're very close of issuing a pull request with a implementation of Tacotron 2 that is compatible with @r9y9's repo. |
|
@r9y9 thanks for your quick reply. |
|
@r9y9 probably beginning of next week we'll issue a PR with Taco 2. Here's the attention and predicted mel after 7k iterations.
|
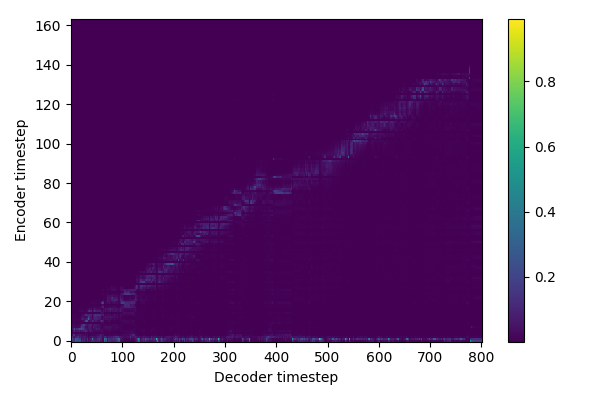

|
@rafaelvalle Great! I cannot wait next week:) |
|
hi @rafaelvalle, i'am working on Taco 2 two, can u explain how to reprodurce your result which looks working? |
|
@neverjoe hold on tight, we're very close to a release of Tacotron 2 with FP16 and Distributed. |
|
great job! |
|
@rafaelvalle What does the timeline look like? Any samples you can share? |
|
We will release it probably on Monday. I'll post a short sample today here!
…On Thu, Mar 22, 2018, 10:09 AM Michael Petrochuk ***@***.***> wrote:
@rafaelvalle <https://github.com/rafaelvalle> What does the timeline look
like?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#11 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ACMij_qQ-KulTl_a_X1PTvwI7uDoh9JJks5tg9rHgaJpZM4RIT6B>
.
|
|
great!
Rafael Valle <notifications@github.com>于2018年3月23日周五 上午8:41写道:
We will release it probably on Monday. I'll post samples today here!
On Thu, Mar 22, 2018, 10:09 AM Michael Petrochuk ***@***.***
>
wrote:
> @rafaelvalle <https://github.com/rafaelvalle> What does the timeline
look
> like?
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <
#11 (comment)
>,
> or mute the thread
> <
https://github.com/notifications/unsubscribe-auth/ACMij_qQ-KulTl_a_X1PTvwI7uDoh9JJks5tg9rHgaJpZM4RIT6B
>
> .
>
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#11 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ABsFmFzuFt7a-Ax9BSmXBmBCCXYV6rZxks5thES_gaJpZM4RIT6B>
.
--
Sent by Inbox
|
|
Mel-spectrogram and alignment during FP16 and DistributedDataParallel training. Short demo sample not in the training set generated with the Griffin-Lim algorithm, not Wavenet Decoder.. |


|
@rafaelvalle What is required to get to samples that sound similar to Googles Tacotron 2? Do you think your getting close? |
|
One can get to Google's quality by using the Wavenet decoder with at least
22khz sampling rate instead of Griffin-Lim. Ryuchi happens to have a repo with the Wavenet Decoder https://github.com/r9y9/wavenet_vocoder/
…On Thu, Mar 22, 2018, 9:48 PM Michael Petrochuk ***@***.***> wrote:
@rafaelvalle <https://github.com/rafaelvalle> What is required to get to
samples that sound similar to Googles Tacotron 2? Do you think your getting
close?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#11 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ACMij5WFcf4wQLH8rwA-P8XEv5mYwdMFks5thH6YgaJpZM4RIT6B>
.
|
|
@rafaelvalle great job! How do you improve your work on https://github.com/Rayhane-mamah/Tacotron-2, would you to explain it? thank you |
|
we'll release the code soon and everything will become evident. i'm sorry this is taking some time but we're going over many bureaucracy layers. |
|
@rafaelvalle Thank you for your contributions ! I'm looking forward to seeing the performance of tacotron-2 |
|
@rafaelvalle any more updates for your tacotron 2?! |
|
Yeah, we decided to release tacotron and wavenet with real time inference.
Still going through block bureaucratic layers
…On Wed, Apr 11, 2018, 7:51 AM duvtedudug ***@***.***> wrote:
@rafaelvalle <https://github.com/rafaelvalle> any more updates for your
tacotron 2?!
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#11 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ACMij-1Z0im4r_H6qN3vxy7x-86XTscCks5tnhiEgaJpZM4RIT6B>
.
|
|
Sounds great @rafaelvalle !!! Open source? For real time inference are you using something like the RNN based 'Efficient Neural Audio Synthesis' by Kalchbrenner et al. ? |
|
@rafaelvalle Do you implement parallel WaveNet! to real time |
|
We use the first wavenet for real-time inference. |
|
can u share your real time wavenet? 64 residual channels, 256 skip
channels, 256 audio channels ?
Rafael Valle <notifications@github.com>于2018年4月26日周四 下午11:31写道:
We use the first wavenet for real-time inference.
Here's NVIDIA's "CUDA alien code" that makes wavenet run faster than
real-time.
https://github.com/NVIDIA/nv-wavenet/
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#11 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ABsFmLcSBIuKFgRcO0yA2xKa1R0vAJcPks5tsehVgaJpZM4RIT6B>
.
--
Sent by Inbox
|
|
Keep an eye on it. |
|
Here's the link to the PyTorch implementation of Tacotron 2. |
|
@rafaelvalle Nice! |
|
Not yet but soon. We're currently focusing on another release. |
|
@rafaelvalle How much can we expect from Nvidia in upkeeping these repositories? The comments and tests are a bit lacking! Does not seem like there have been further updates to: https://github.com/NVIDIA/nv-wavenet |
|
Hey @PetrochukM, please post any requests, issues, suggestion on the specific repos and the team responsible for it will address it precisely. |
|
@rafaelvalle Okay! Curious, how large of an effort is this? Assuming this is not a PyTorch like an effort by Facebook or a Tensorflow like effort. |
|
You can probably find that information on the github repos as well... |
|
r9y9/wavenet_vocoder#30 (comment) Tacotron2 + WaveNet online TTS demo is comming soon. |
finally...! ref: #30 ref: r9y9/deepvoice3_pytorch#11 ref: Rayhane-mamah/Tacotron-2#30 (comment)
I think I can finally close the issue. |
Sorry if this is off-topic (deepvoice vs tacotron) but it seems like the tacotron 2 paper is now released.
The speech samples sounds better than ever (I think):
https://google.github.io/tacotron/publications/tacotron2/index.html
I must admit that I'm not too well versed in how much this differs from the original tacotron. But perhaps the changes made also could be used in your projects?
The text was updated successfully, but these errors were encountered: